1. 关于事件溯源
MartinFowler在2005年的博客中提及了“EventSourcing”这个词语,他将事件描述为一个应用的一系列状态改变,这一系列事件能够捕获用来重建当前状态的一切事实真相。他认为事件是不可变的,事件日志是一种只会不断追加(appendonly)的存储。事件从来不会被删除,这意味着事件可以被重播。
事件溯源(EventSourcing),即通过发生过的事件追溯当前状态的原因,这些事件是造成当前状态的唯一真相来源。
举例说明:支付宝的账户余额与进出明细存在一种关系:进出明细应该是导致账户余额变动的原因,其中存储了构成账户余额的各个事件,影响当前账户余额的是这些事件的总和。
事件溯源的基本思想是确保在事件对象中捕获应用程序状态的每个更改,并且将这些事件对象按照它们发生的顺序存储(事件明细),这些存储的信息称为事件日志,它可作为直接存储状态本身的替代。不仅可以通过事件日志查询这些事件,还可以使用事件日志重建过去的状态,并作为自动调整状态以应对追溯更改的基础。
只存储事件而不存储状态,这样不至于在同时发生大量并发访问时,对数据库中的状态进行竞争式的修改,从而巧妙回避了通过加锁防止并发修改又导致的性能问题。
如果将事件集合中的运行看成电影一样的流动,那么状态如同在某个时刻对流动的事件实现的快照,代表那个时刻系统的状态。当前状态始终可以从事件中派生。这个过程被称为投影(Projection)
投射成的状态结果可以有几种保存方式:内存、关系数据库、NoSQL和文件系统,操作方式可以是同步或异步,投射的过程中可能存在性能问题,可以通过缓存设计或其他提前计算并存储状态的方式解决。
事件溯源的事件不一定是领域事件,追溯事件是来自聚合发出的用于重建状态的领域事件,而领域事件是更广泛的一种事件,可以用于在不同有界上下文之间实现通信。
传统以数据库E-R图为核心的架构只保留和维护对象的当前状态,而事件溯源维护状态的所有更改操作:
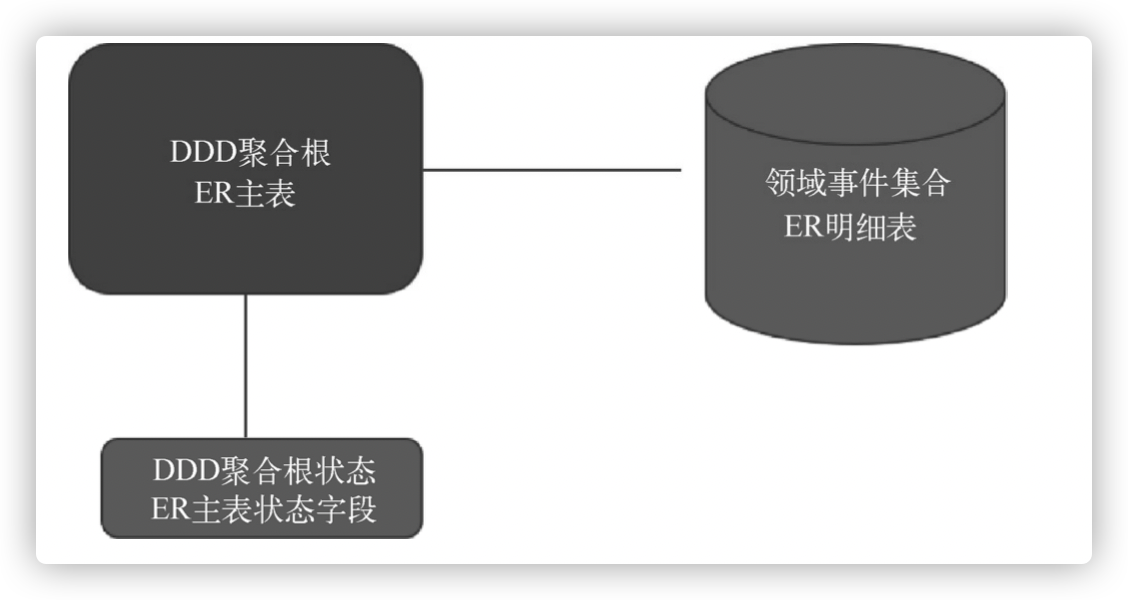
事件溯源强调了状态变更(事件)高于状态本身,这种不同的视角为建模思考提供了新的切入点。
实践中,可以使用Apache Kafka等技术组件记录事件日志,实现事件溯源。
2. 基于事件溯源的聚合根设计
事件溯源是一种用事件日志追溯状态的方法,因此事件溯源的关键在于事件日志。事件日志是一种事件集合,代表聚合根发生的一系列事件,使用事件溯源的关键就是需要在聚合根中引入事件集合或事件日志。
2.1. 用事件替代状态
如果从事件溯源角度来确定聚合根,聚合根实际上不只是聚合结构的代表,也是事件集合的代表。聚合的结构关系只是描述了聚合中的不变部分,表示整体由部分构成的结构关系,这类似于ER模型中外键表达的关联表。但是聚合根除了这种不变性结构关系以外,作为实体,而不是值对象,它还包含可变的状态,这些状态在业务执行过程中不断被改变,也影响业务后续步骤的执行。
因此,一个聚合根模型是由两个部分组成的:不变的整体部分关系和可变的状态。状态是一个非常抽象的词,实体中总有一些数据字段需要改变,是否需要变化的字段都是状态?状态含义是什么?在这之中,可以使用可变的事件集合或事件日志可以用来记录和描述抽象且可变的状态。
2.2. 用活动替代聚合根
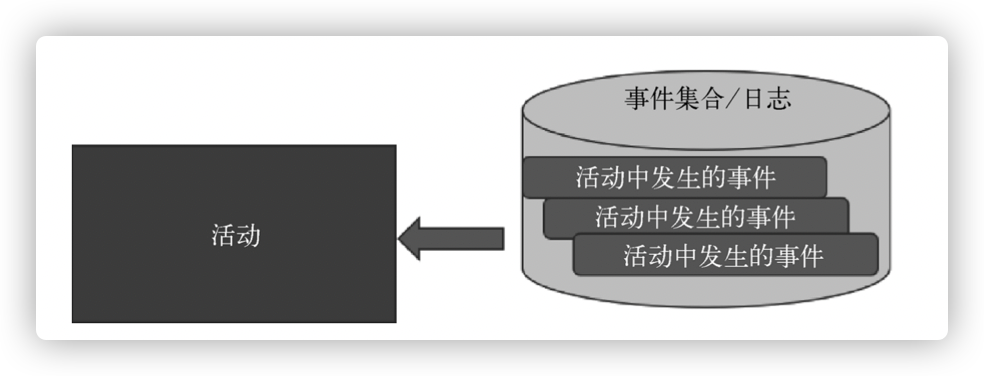
当采取事件溯源方式建模聚合根时,聚合根一般代表现实世界中的活动概念,在这个活动中发生了各种事件,这样就完全从动词方面进行领域建模。活动本来是一个动词,但是使用聚合根这个类表示活动,在这个活动中会发生各种事件,而活动也是有上下文条件的,这就指出了当前的有界上下文。
比如足球比赛,足球比赛是一个聚合根,一个活动,中间会有很多事件,比如比赛开始,比赛结束等。
用活动/事件概念建模聚合根实体的方式,这种方式适合一些流程性或过程性的案例,活动代表一种大的有时间性的过程,而事件代表活动中发生的各种事件,活动是包含各种事件的,这种语义非常符合自然生活的描述,因此,这样建模比较容易直接,过渡到事件溯源也是非常自然:

3. 事件溯源优点
- 提供监管区域(如金融业)、政府法规中规定的审计日志。在许多国家,要求公司保存系统运行的记录。例如,美国的法规要求公司以不可重写、不可擦除的格式保存记录事件来源,由于事件溯源只附加事件日志和不可变事件特性,所以非常适合这一要求。
- 一次写入多读(WORM,Write Once Read Many)数据存储等技术可与事件溯源互补使用,WORM存储能在硬件级别防止数据更改,并且只允许附加新数据。
- 在硬件级别就防止数据更改,并且只允许附加新数据
- 调试那些已经捕获的事件可用于进一步了解系统为什么会达到当前状态,哪些事件造成了当前状态。事件溯源在可跟踪性和调试能力方面体现了优势。
- 事件溯源还有可伸缩性的优势,只追加的事件日志是同步复制状态的唯一方法。相比状态字段锁而言,由于复制不可变的事件日志几乎不需要用锁,在CQRS中,复制事件日志比直接复制状态更易于扩展。
- 信息价值也是应用事件溯源的一个动机,检查事件日志可以重建或查询系统的所有过去状态。这可以为系统提供很大的价值,特别是当分析交互作用时。在这样的系统中,通常不知道将来要做什么样的分析。例如一个在线商店,商家老板希望列出顾客放入购物车或取走的所有商品列表,这样能够比较商品的受欢迎程度,使用事件溯源架构可以很容易遍历这个购物车事件集合并罗列出来。
3.1. 替代分布式事务
采取事件溯源时,应用不是直接将记录写入两个存储系统,而是将更新事件追加到事件日志中,数据库和搜索引擎库各自订阅此日志,并按照它们在日志中出现的顺序将更新写入自己的存储中。通过日志对更新进行排序,数据库和搜索索引以相同的顺序应用相同的写入集,使它们彼此保持一致。
3.2. 事件日志的顺序性
事件的顺序性是事件溯源的根本保证,没有前后顺序(如付款事件可能先于下订单事件),就会造成整个系统的处理混乱。事件顺序性通过设置某个时刻只有一个操作者对事件日志的追加事件来实现。
如果事件日志不是集中存放,而是每个参与者都有一份完整的日志(例如在分布式环境中,事件日志是复制给多个节点之间存放的),那么如果需要对事件日志进行追加,也必须满足只能由一个节点实现追加的条件,多个节点基于共识(Paxos或Raft)算法选出主节点进行事件追加。
4. 总结
系统记录的是事件,而不是状态,但是事件的发现有赖于状态的发现。状态机存在于每个系统中,对状态变化的敏感有助于发现导致状态变化的原因。
现代软件架构或已走上了这样的设计思路:
- 在接受前端请求向后端写入数据的方向上,采取事件溯源或区块链技术;
- 在从后端向前端返回查询数据的方向上,则采取人工智能和大数据分析,将更符合用户体验的数据定制化推向用户。
其实,这是一种大型的CQRS架构,写入数据方面,内部数据采取事件溯源,将用户的各种原始操作事件记录下来,作为大数据分析的数据来源进行查询。