基于Redis实现缓存系统的注意点与一些常见问题
1. 从计算机系统的缓存开始
在计算机系统中,默认有两种缓存:
- CPU 里面的末级缓存,即 LLC,用来缓存内存中的数据,避免每次从内存中存取数据;
- 内存中的高速页缓存,即 page cache,用来缓存磁盘中的数据,避免每次从磁盘中存取数据。
LLC一般几MB,page cache一般几GB,磁盘一般几TB,可以看出缓存系统有以下特征:
- 在一个层次化的系统中,缓存一定是一个快速子系统,数据存在缓存中时,能避免每次从慢速子系统中存取数据。
- 缓存系统的容量大小总是小于后端慢速系统的,我们不可能把所有数据都放在缓存系统中。
2. Redis的缓存策略
所谓缓存,就是将需要多次读取的数据暂存起来,这样在后面,应用程序需要多次读取的时候,就不必从数据源重复加载数据了,这样就可以降低数据源的计算负载压力,提高数据响应速度。
一般来说,有三种策略:
- **旁路缓存(Cache Aside)策略:读操作命中缓存直接返回,否则从后端数据库加载到缓存再返回,并写入缓存中。写操作直接更新数据库,然后删除缓存。这种策略的优点是一切以后端数据库为准,可以保证缓存和数据库的一致性。缺点是写操作会让缓存失效,再次读取时需要从数据库中加载。**Redis一般都是使用这个策略。
- **通读缓存(Read Throught)策略:应用层读写只需要操作缓存,不需要关心后端数据库。应用层在操作缓存时,缓存层会自动从数据库中加载或写回到数据库中,这种策略的优点是,缓存中拥有最新的数据,对于应用层的使用非常友好,只需要操作缓存即可,缺点是需要缓存层支持和后端数据库的联动。**Redis无法自动与Mysql等后端数据库联动,需要额外写业务代码来实现这个策略。
- 写回策略(Write Back)策略:这里主要是指异步写回策略,同步就是通读缓存了。写操作只写入缓存,等数据就要过期(淘汰)时写入到数据库中。优点是写入飞快,缺点是数据丢失风险较大。
3. 缓存大小的设置
一般遵循“八二原理”设置为总数据量的 15% 到 30%,兼顾访问性能和内存空间开销。
4. 缓存删除方案
Redis的内存总是会满的,因此我们需要设置相应的的删除方案,对内存数据进行清理。
总结来说就是三块:
- 定期删除
- 惰性删除
- 内存淘汰
4.1. 定期删除
Redis每隔一端时间会检查一部分已经过期的key进行删除。
4.2. 惰性删除
Redis会在获取某个Key时检查是否过期,过期就删除
4.3. 内存淘汰(内存驱逐)
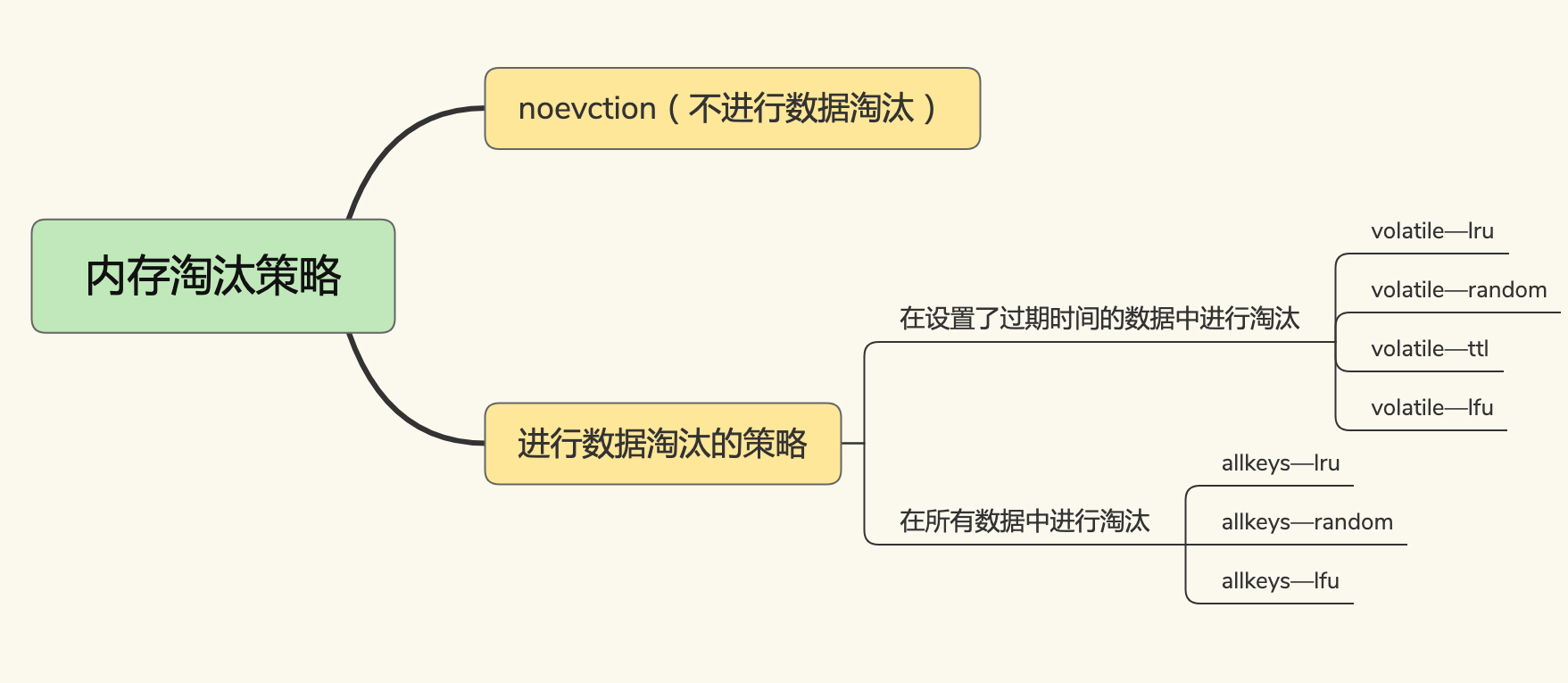
需要注意,volatile-lfu和allkeys-lfu是Redis 4.0 后新增的。
- noevction不进行数据淘汰
- volatile-ttl 在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
- volatile-random 就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
- volatile-lru 会使用 LRU 算法筛选设置了过期时间的键值对。
- volatile-lfu 会使用 LFU 算法选择设置了过期时间的键值对。
- allkeys-random 策略,从所有键值对中随机选择并删除数据;
- allkeys-lru 策略,使用 LRU 算法在所有数据中进行筛选。
- allkeys-lfu 策略,使用 LFU 算法在所有数据中进行筛选。
注意:
- LRU算法,全称Least recently used,即最近最少使用
- LFU算法,全称Least Frequently Used,即最不经常使用
LRU 会把所有的数据组织成一个链表,链表的头和尾分别表示 MRU 端和 LRU 端,分别代表最近最常使用的数据和最近最不常用的数据:
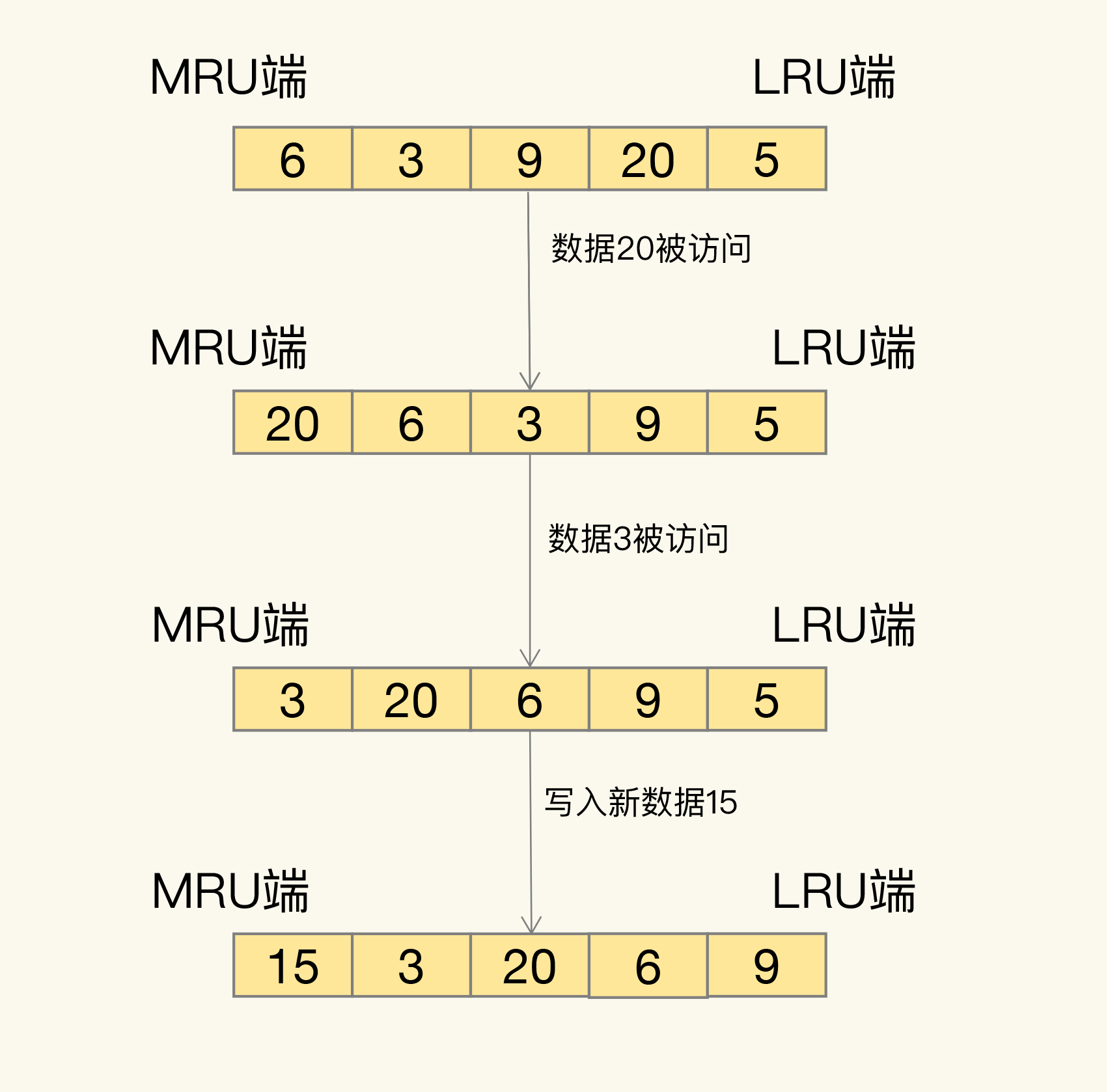
LRU 算法背后的想法非常朴素:它认为刚刚被访问的数据,肯定还会被再次访问,所以就把它放在 MRU 端;长久不访问的数据,肯定就不会再被访问了,所以就让它逐渐后移到 LRU 端,在缓存满时,就优先删除它。
在 Redis 中,LRU 算法被做了简化,以减轻数据淘汰对缓存性能的影响(否则需要维护链表)。具体来说,Redis 默认会记录每个数据的最近一次访问的时间戳(由键值对数据结构 RedisObject 中的 lru 字段记录)。然后,Redis 在决定淘汰的数据时,第一次会随机选出 N 个数据,把它们作为一个候选集合。接下来,Redis 会比较这 N 个数据的 lru 字段,把 lru 字段值最小的数据从缓存中淘汰出去。
LFU 缓存策略是在 LRU 策略基础上,为每个数据增加了一个计数器,来统计这个数据的访问次数。当使用 LFU 策略筛选淘汰数据时,首先会根据数据的访问次数进行筛选,把访问次数最低的数据淘汰出缓存。如果两个数据的访问次数相同,LFU 策略再比较这两个数据的访问时效性,把距离上一次访问时间更久的数据淘汰出缓存。
总结来看:
- LRU策略是只有时间维度因素,更加关注数据的时效性
- LFU策略按优先级,有访问次数纬度因素 + 时间维度因素,更加关注数据的访问频次。
特别注意,在设置数据的过期时间时,尽量指定过期时间,而不是指定多久后后删除,在主从环境中会出现不一致的情况(从库保留数据时间 = 从库同步到数据 + 过期时间,而从库同步到数据的时间 在 主库写入数据的时间之后)
5. 缓存使用过程中的一些问题
5.1. Redis缓存与数据库不一致问题
这里用蒋德钧老师的一张图:
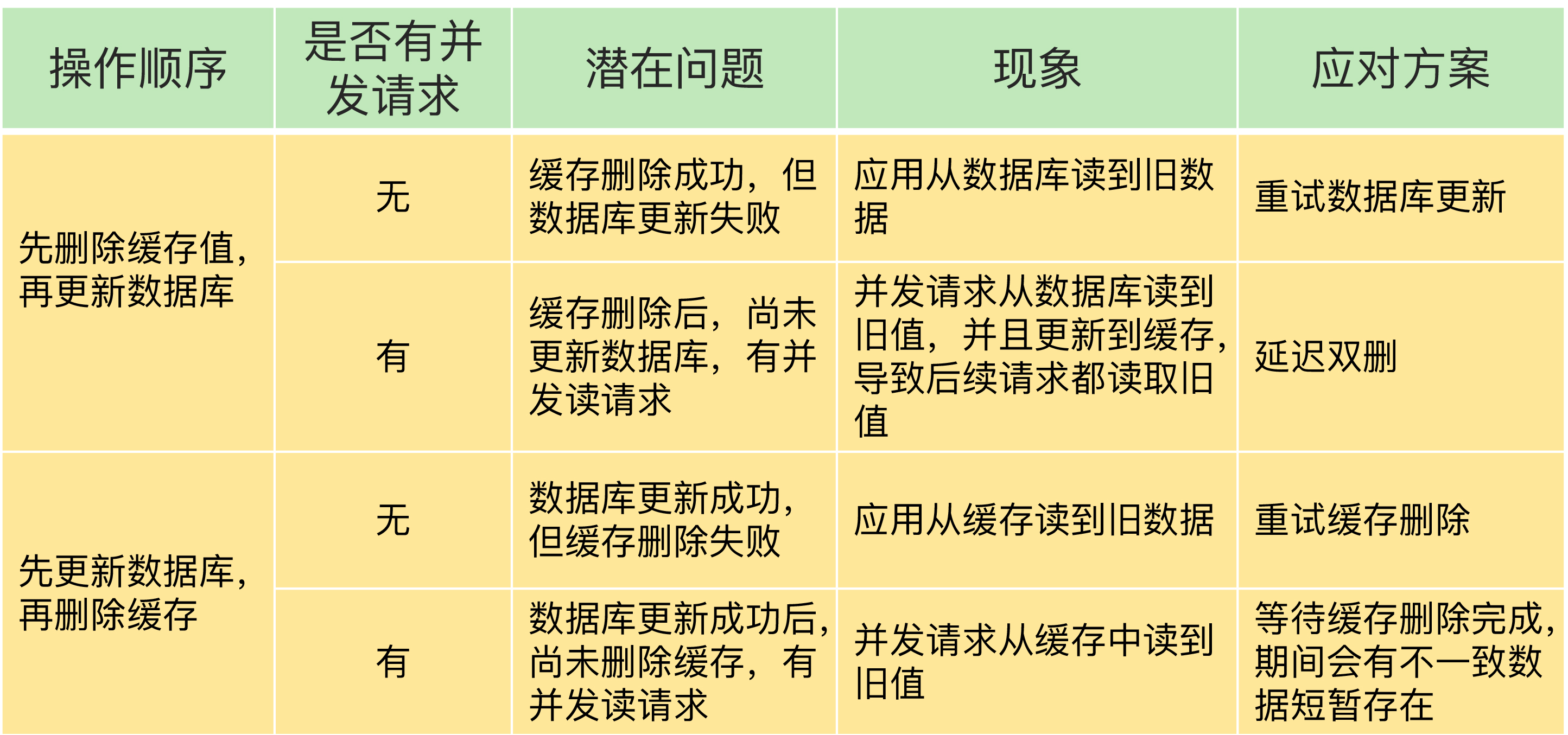
重点说下一个容易造成困惑的概念:
- 延迟双删:在线程 A 更新完数据库值以后,让它先 sleep 一小段时间,再进行一次缓存删除操作,这样后续访问的线程就可以触发缓存缺失,进而将新数据写入缓存。
5.2. 缓存雪崩
缓存雪崩是指大量的应用请求无法在 Redis 缓存中进行处理,紧接着,应用将大量请求发送到数据库层,导致数据库层的压力激增。
可能有两个原因:
- 缓存中有大量数据同时过期,导致大量请求无法得到处理。
- Redis服务器宕机。
针对第1点,有以下方案:
- 调整过期时间,适当加一个随机数时间避免同时过期
- 服务降级(核心业务直接访问数据库 | 非核心业务返回空值等)
针对第2点,有以下方案:
- 是在业务系统中实现服务熔断或请求限流机(暂停业务应用对缓存系统的接口访问,直接返回)。
- 事前预防,搭建高可用的主从集群
5.3. 缓存击穿
缓存击穿是指,针对某个访问非常频繁的热点数据的请求,无法在缓存中进行处理,紧接着,访问该数据的大量请求,一下子都发送到了后端数据库,导致了数据库压力激增,会影响数据库处理其他请求。
一般考虑是对于访问特别频繁的热点数据,不设置过期时间。
5.4. 缓存穿透
缓存穿透是指要访问的数据既不在 Redis 缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。
有以下方案:
- 缓存设置空值或缺省值。
- 布隆过滤器快速判断数据是否存在,避免从数据库中查询数据是否存在,减轻数据库压力。
- 前端请求检测
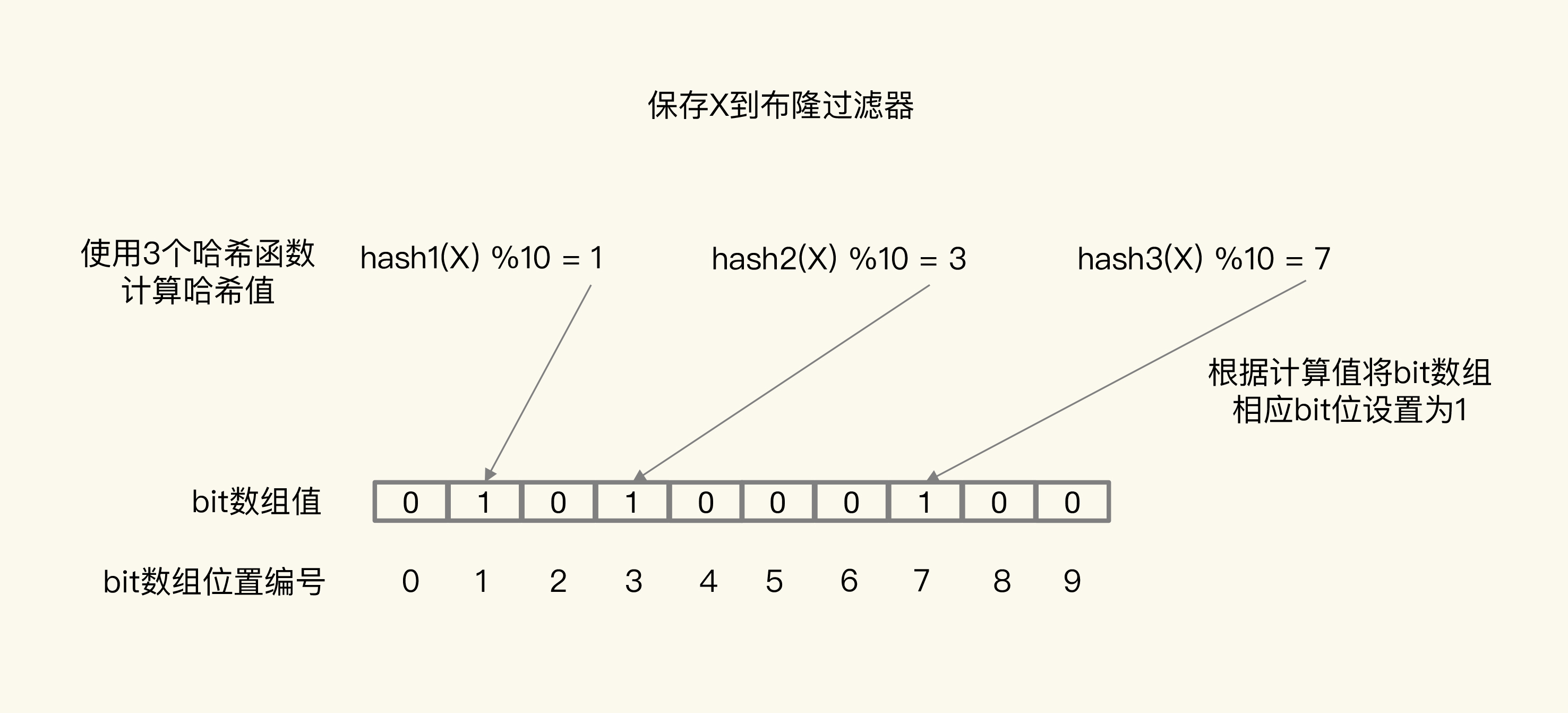
下面重点说以下布隆过滤器,这是一个概率学的算法实现,布隆过滤器有以下特点:
符合布隆过滤器不一定存在,不符合布隆过滤器一定不存在。
布隆过滤器由一个初值都为 0 的 bit 数组和 N 个哈希函数组成,可以用来快速判断某个数据是否存在。当我们想标记某个数据存在时(例如,数据已被写入数据库),布隆过滤器会通过三个操作完成标记:
- 首先,使用 N 个哈希函数,分别计算这个数据的哈希值,得到 N 个哈希值。
- 然后,我们把这 N 个哈希值对 bit 数组的长度取模,得到每个哈希值在数组中的对应位置。
- 最后,我们把对应位置的 bit 位设置为 1,这就完成了在布隆过滤器中标记数据的操作。
这样,当应用想要查询 X 时,只要 比较原来为1的位置 是否包含于 x计算后为1的位置中,一旦又一个不符合(为0),则不在缓存中,否则可能在。
5.5. 缓存污染
在一些场景下,有些数据被访问的次数非常少,甚至只会被访问一次。当这些数据服务完访问请求后,如果还继续留存在缓存中的话,就只会白白占用缓存空间。这种情况,就是缓存污染。
需要根据业务设置合适的缓存淘汰(驱逐)策略。
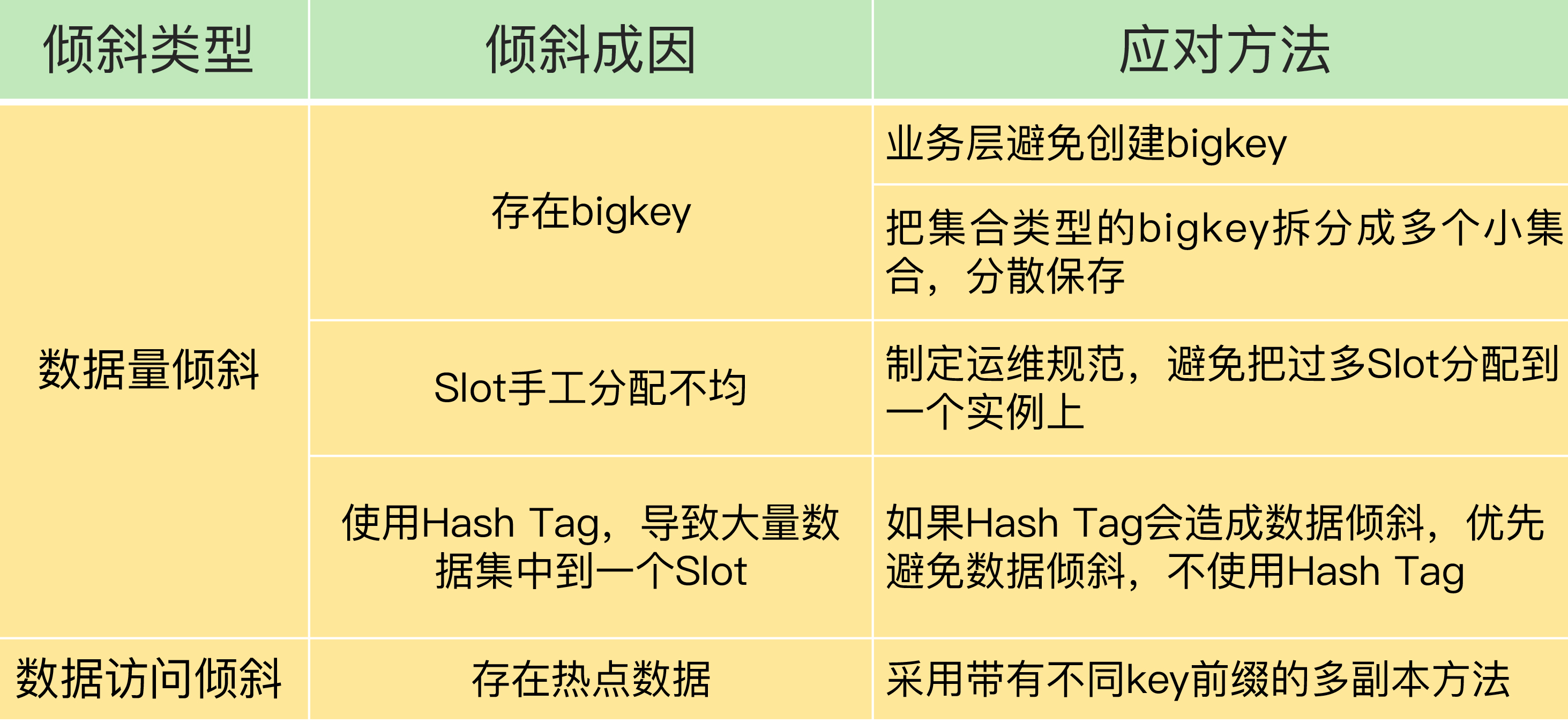
5.6. 数据倾斜
在Redis切片集群中比较容易遇到的一个问题:数据倾斜:
- 数据量倾斜:在某些情况下,实例上的数据分布不均衡,某个实例上的数据特别多。
- 数据访问倾斜:虽然每个集群实例上的数据量相差不大,但是某个实例上的数据是热点数据,被访问得非常频繁。
这里po一个表格:
6. 参考
- 李智慧的极客时间课程
- 水滴与银弹的博客
- Redis的过期策略有哪些
