1. 充血/贫血模型
1.1. 理解充血模型与贫血模型
DDD领域模型=数据结构+操作方法,数据和行为结合在一起才是一个完整的真正业务对象(领域对象),也才能够真正发挥对象封装的作用,这样的对象或类称为“充血模型”。
贫血模型的对象或类一般只有setter/getter方法,是一种纯粹的数据结构,没有任何业务意义/行为,往往只作为服务(Service)中的方法参数被传入。
/*********************贫血模型*********************/
// 定义用户类
public class User {
private String code;
private String name;
private Integer age;
}
// 如果需要保存,一般会在service层调用ORM框架:
public class UserService {
// Inject
private UserMapper userMapper;
// 失血/贫血模型作为方法的参数传入,被操作
public void save(User user) {
userMapper.save(user);
}
}
/*********************充血模型*********************/
// 定义用户类
public class User {
private String code;
private String name;
private Integer age;
// 保存用户作为一个业务行为方法,是当前领域模型的方法。
public void save(User user) {
// ...
}
}
关于充血模型中的业务行为方法:
- 如何获得?从业务领域的问题空间来,一个领域模型应该有哪些职责和基本行为
- 业务行为设计取决于设计角度,设计角度取决于类所在的有界上下文或聚合边界。同样的领域模型类,可能在不同的有界上下文中有不同的职责行为。
服务被开发人员用作真正的银弹,但最终成为得到贫血模型的最大原因。职责行为都在服务模型中,血液都充到服务模型里了,实体自己却变成了贫血模型。
充血模式与失血模型的最大区别是:充血模型有自己的业务行为方法,这些方法正是说明了模型的业务特征,而且是基本业务特征(不能将这个模型涉及的所有场景上下文的功能都加进来,否则这就变成了一个上帝式的对象)。
聚合根对象就应该是一个充血模型,聚合根通过自己的行为和聚合结构维持整个聚合边界的逻辑一致性或不变性约束。
1.2. 充血模型和贫血模型结合使用
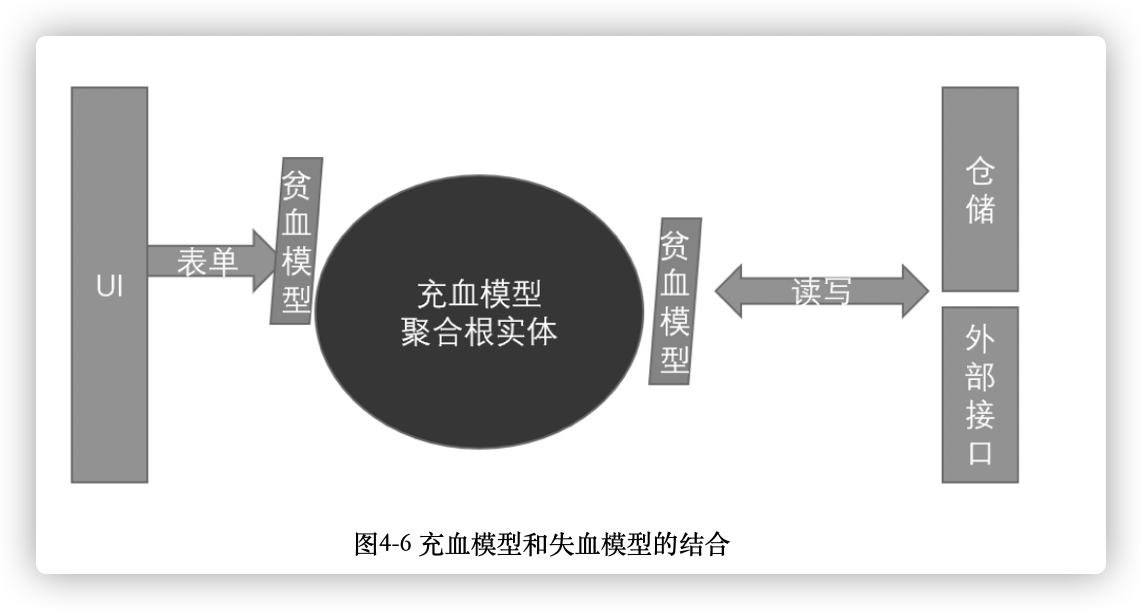
图中,
- 接受前端参数可以使用失血模型DTO或者值对象进行包装。
- 通过领域服务传递给聚合根实体,由聚合根实体根据业务规则决定是否执行、接纳这些数据,以及造成哪些状态变化、发生哪些事情。
- 受限于部分仓储模块的ORM框架,比如Hibernate的实体是一个贫血模型,因此需将贫血模型和DDD聚合根实体的充血模型分离(图中充血模型转化为贫血模型),不要在ORM的实体模型基础上设计、建立DDD的聚合根实体模型。
除此以外,还需要将公有setter方法变为私有。
这样在构造完充血模型对象后,外部调用者无法直接修改充血模型对象的属性。如果有一个聚合结构,A包含B、C,或者说A由B、C组成,那么对B、C的操作只能在A中进行,B或C无法调用A的setter操作,就无法更改A中属性,这体现了A作为聚合根的带头作用,正如在一个小组中,只有上级才能下达命令给小组长,小组成员是无法对小组长下达命令的,这样保证了A的数据所有权边界,不用担心A在各种复杂的使用情况下会被无意或有意地修改。setter私有方法只能在实体模型中自己调用,例如在构造函数中,或者在Builder构建模式中。
2. 实体
DDD实体=唯一标志+业务行为方法,因此DDD实体也是一种充血模型。
以上文中代码为例:
/*********************充血模型*********************/
// 定义用户类
public class User {
private String code;
private String name;
private Integer age;
// 保存用户作为一个业务行为方法,是当前领域模型的方法。
public void save(User user) {
// ...
}
}
首先,code是当前user实体的唯一标志;其次他有业务逻辑“保存用户”,通过业务行为(方法)暴露给外界。
2.1. 实体的标记
聚合根是聚合的唯一标识,聚合也可以看成有界上下文的标识。
标识不是现实中实体固有的,它是主观和客观之间的一种识别符号。正因为标识不是客观世界固有的,而是带有主观偏见和主观视角,所以标识是否存在取决于关注的重点是什么,而关注的重点决定了解决方案是什么,从而决定了软件系统是什么样的。
标志存在的意义是区分关注的重点。
比如订单聚合中的地址类Address,Address是核心目标,需要使用一个标志来记录每一个地址信息。但是如果将Address放入订单上下文中,地址只是订单的一个送货地址信息,关注的重点是订单,因此每个订单需要一个单独的标志。
实体的标识主要涉及实体对象实例的创建以及它从生到死的生命周期管理,这个过程需要标识来标记,如果没有标识,将无法管理一个个实体对象实例,也就无法管理它们代表的业务数据和逻辑,也无法在仓储或数据库中找到它。
标识可以使用实体自身的一些ID,例如身份证号等,也可以由软件系统自动生成唯一ID分配给实体,或者使用计算机语言自动生成的随机数UUID。
2.2. 实体的设计
实体设计的两个关键:实体命名和标识发现。
实体命名更倾向于类别命名,比如垃圾分类中的“干垃圾”与“湿垃圾”; 标志可以加上时间标记是非常有效的,比如“干垃圾某年某月末日”。
实体与标识的关系非常类似于聚合与聚合根的关系,聚合根是聚合的标识。其实有时设计一个实体,如果其内部由多个部件组成,那么它既是一个实体,也是一个聚合的聚合根,两者身份一致;如果一个实体只是由基本字段属性组成,不引用其他子对象,那么这个实体就不是一个聚合根。
看一个例子感受一下:
public class A {
}
// 当A引用了B对象时:
public class B {
private A a;
}
A引用了B,说明A这个实体是一个组合体了,结构有两个层次,是不是具备做聚合根的潜力?如果A是聚合根,那么A就是整个聚合的标识;A的内部也有标识字段id,那么id可不可以作为整个聚合的标识呢?实际上是的,只不过它是一个标识字段,业务意义不是非常明确,使用其实体类名作为标识更加通用,而id才可能是计算机世界内的标识。例如Car是一个汽车的聚合根,它代表整体概念,由轮子、车厢和发动机等组成。因为Car是一个抽象的整体,无法在汽车中找到一个代表Car的部件,怎么办?使用发动机部件代表它,那么Car可能就有两个聚合根,发动机作为其标识也是一个聚合根,而发动机作为标识的主要依据是其内部标识属性:发动机号。
- 聚合是从实体外部看实体的上下文环境,需要在这个场景上下文扮演的角色来定位。
- 实体本身的内部设计,包括标识和其他属性、职责以及关联属于事物内部的构造设计。实体的设计不只要照顾到所处上下文,还要兼顾它被创建后的生命周期管理,实体的类名负责它在上下文中的定位,而实体的标识负责它被创建后的生命。
命令和事件是针对一个聚合的,落实到具体方面,也就是针对一个聚合根实体。
从整体概念和唯一标识两个方面入手设计实体,可以兼顾其作为聚合根的职责和作为实体的职责。当然,如果一个实体的整体概念没有大到包含很多部件,那么它就是一个基本实体,或者是一个自我聚合的独立个体实体。但是实际中这种现象比较少,一旦一个实体有些复杂,那么就可能隐藏聚合概念在其中,例如发帖本来很简单,帖子只由标题和内容组成,但是它可能有回帖,这就产生了帖子与帖子的关系,复杂性出现了,聚合概念由此就需要了。有关系的地方就要聚合,聚合是1:1和1:N的关系,通过聚合排除了N:1和N:N的关系,这样能方便理清根和节点的区别,形成树形结构,便于理解,将复杂事情简单化,理清关系后,再贴上唯一标识这个标签,这样就纲举目张了。
2.3. 实体对象的创建
唯一标识ID = 类型区别 + 数值区别,当一个对象以这样的ID作为输入参数被创建时,就具备了这2个区别。
public class Person {
private String id;
public Person(String id) {
this.id = id;
}
}
但是有时候,也会因为技术原因,必须要有无参的构造函数。
为了强调构造函数只能有一种,可以通过专门的工厂模式和Builder模式,将无参构造函数标记为私有,禁止直接通过无参构造函数new出对象,只能通过内部的工厂方法或者Builder方法进行构造,这样就是一种明确的方式说明,这个实体对象创建是需要非常注意的。
Builder模式还有一些额外的好处,它迫使开发人员去思考实体对象:
- 哪些属性是必须的,哪些属性是可选的
- 哪些属性的生命周期必须绑定父对象的生命周期
- 必须决定哪些属性在创建对象后不能在被更新(标记为final,尽可能保持对象不变形,将有限精力用来对付可变属性);必须决定哪些属性可以被更新
3. 值对象
如果实体没有唯一标识就直接构建,那么这样的实体就不符合实体的定义了,就可能不是实体,而是值对象。
值对象是没有唯一标识的对象,是一堆数据值的容器。这些数据值并不需要或根本就没有共同特征。
值对象也是一个充血模型。
但是值对象(VO)与数据传输对象(DTO)还是有区别的:
-
首先,值对象中的数据值一旦被构建,就不能改变,这是不变性的特性,而DTO没有这种约束,这容易导致DTO传输过程中不断添加、修改各种字段。DTO变成一个装载数据的可变长度的容器,虽然给编程带来了方便,但是将可变性带到代码的各个地方,最后DTO进数据库存储时,才发现数据并不是原来想象的那样,至于在哪个环节修改了,就需要不断地跟踪,这种跟踪在复杂软件中也非常复杂。值对象的不变性克服了DTO的这种缺点,如果希望改变其中的值,可重新构建一个新的值对象,这样有别于原来的对象,也可以使用克隆模型克隆(clone)原来的一些数据,甚至有很多框架支持对象之间的数据克隆。值对象在Java中通过使用final关键字实现
-
其次,值对象的构建一般是由聚合根实体负责的,任何聚合外界需要使用聚合内的信息,都需要通过聚合根访问。聚合根不能将自己内部的对象直接奉献给外部,因为一旦被外界修改了,自己都不知道,就可能造成内部逻辑的不一致,就像有外键关联的两个数据表,一个表修改了数据,而另外一个没有修改,这种情况是可怕的,不过因为外键约束的存在,数据库会进行这两个表的原子更新,但是内存中的对象没有这样的技术机制,而需要通过专门的设计来保证,因此不将聚合内部的对象直接暴露给外界是基本原则,外界如果需要一些数据,可以根据聚合内对象构造一个值对象使用。
-
一定情况下,值对象可以全局共享一个实例,减少内存消耗
-
用值对象封装传参,避免传参错误,同时,通过包装数据值,值对象提供了更易阅读和理解的上下文。
// 发送邮件,方法传参需要先title再body,容易写反 public class EmailSender { public boolean send(String title, String body) { return doSend(title, body) } } // 封装入参为值对象,通过一些Builder模式强行说明参数顺序 public class EmailContent { private final String title; private final String body; }
3.1. 值对象与实体的区别
- 是否有唯一标识是分辨实体和值对象的主要依据。
- 也有其他特征可以作为辅助依据,例如不变性。值对象一旦构成就是不变的,而实体中是有可能变化的状态。
- 事件溯源是一种将可变状态转变为不变的值对象类型的领域事件,从而消除了聚合根实体中的可变状态,这样实体也就可能变成一种不可变的对象。
3.2. 用值对象重构方法
用充血模型的值对象重构方法的输入输出,可以让代码更简洁,隐藏多余的细节;除此以外,值对象不可变的特性可以让方法更加易读。
4. 领域服务
无法放入实体和值对象的行为操作,或者涉及多个实体的操作都可以放入领域服务中。
领域服务是职责的传递者,不是决定者,真正决策和决定的是聚合根,也就是聚合根实体,服务只是将用户的请求传递给实体,实体做出决策后再返回给用户。
领域服务通常是介于内部和外部之间的协作者,因为服务本身的定义蕴含两个概念:提供服务者和使用服务者,所以服务中的内容经常是为了匹配不同的服务使用者要求,而做出的折中、协调和协作的职责行为。正如会议协调人并不是会议主讲人一样。
4.1. 领域服务的特征
- 其中的行为是无法放入实体和值对象的行为,或者涉及多个实体与值对象的行为。
- 领域服务接口是根据领域模型的其他元素定义的。领域服务接口中的一些动作行为,它们的输入输出参数中并没有涉及实体和值对象的元素,要涉及实体和值对象,关键是先有实体和值对象存在。**有时值对象就存在于服务的输入和输出参数中,当将这些参数用值对象封装起来以后,服务就可以从值对象外部对其操作,同时可以协调几个实体和值对象一起操作,在它们之间完成转换、翻译、数据传递等。**因此,需要首先设计出实体和值对象,特别是值对象经常容易被忽视,被DTO或基本类型掩盖,造成相关行为操作没有地方放置,只好放置在服务中,这是非常值得注意的。
- 操作必须是无状态的。也就是说,不要在服务中保存状态,这样任何一个客户都可以使用这个服务的所有实例,不要将服务与具体客户端绑定,例如服务中保存有客户端的session(会话)信息。状态都是实体模型的属性,服务可以委托实体改变状态,但是不能将这些状态作为自己的字段属性。在服务中可以操作状态,但这些状态不应该是该服务的固有内容,而应该是其他对象传递给服务的,可以将状态作为方法的输入参数,修改后再返回该状态。
- 领域服务可用于有界上下文的验证。当发现一个有界上下文时,其中实体和值对象的调用和测试场景应该是在服务中进行的。
4.2. Clean架构
将领域服务从应用服务和基础设施服务分离出来,虽然服务种类比较多,但是能够将领域干净地和技术分离,这种分离被鲍勃大叔发展为Clean架构(干净架构或清洁架构)。Clean架构的关键就是业务领域不依赖技术平台,与周围支撑的技术环境分离,如同鱼和水的关系,鱼是DDD领域模型,包括实体、值对象和领域服务,而水则是应用服务和基础设施服务代表的技术应用环境。
5. 仓储
仓储(Repository)类似保存对象的仓库,对于不常用的对象,需要放入一个仓库持久保存,对于在内存中活动的对象也是如此,仓储是永久保存对象的地方。
仓储在DDD中是一个模式,引入这个概念,可以隔离业务领域和多种储存方式。
这部分是一个很具体的设计模式,可以看一个原书中提到的例子实现:
核心总结如下:
一群对象需要在整个生命周期中维护边界内的完整性,避免模型由于管理生命周期的复杂性而陷入困境。可通过三种方式来处理。
- 聚合(Aggregate):定义清晰的数据所有权和边界使模型更加紧凑,避免出现盘根错节的对象关系网。聚合圈出一个范围,在这个范围中,无论对象在哪个生命周期,都要保持不变性。
- 通过工厂模式或Builder模式实现聚合内对象的创建(Factory),生命周期之始,使用工厂和组合提供访问和控制模型对象的方法。
- 通过仓储(Respository)模式隐藏不同的存储形式,包括关系数据库、缓存、全文存储等,杜绝复杂的持久层技术对领域模型的干扰。
总之,建立聚合的模型,需要同时把工厂和组合加入设计中来,可以系统地对模型对象的生命周期进行管理。