1. 编译器分类
- 前端编译器:.java文件转变为.class文件的过程(比如Javac)
- 后端编译器:
- 即时编译器(JIT编译器,Just In Time Compiler):运行期把字节码转变成本地机器码的过程(比如HotSpot的C1、C2编译器,Graal编译器)
- 提前编译器:把程序编译成与目标机器指令集相关的二进制代码的过程(比如GCJ)
2. 前端编译器&优化
2.1. Javac编译器

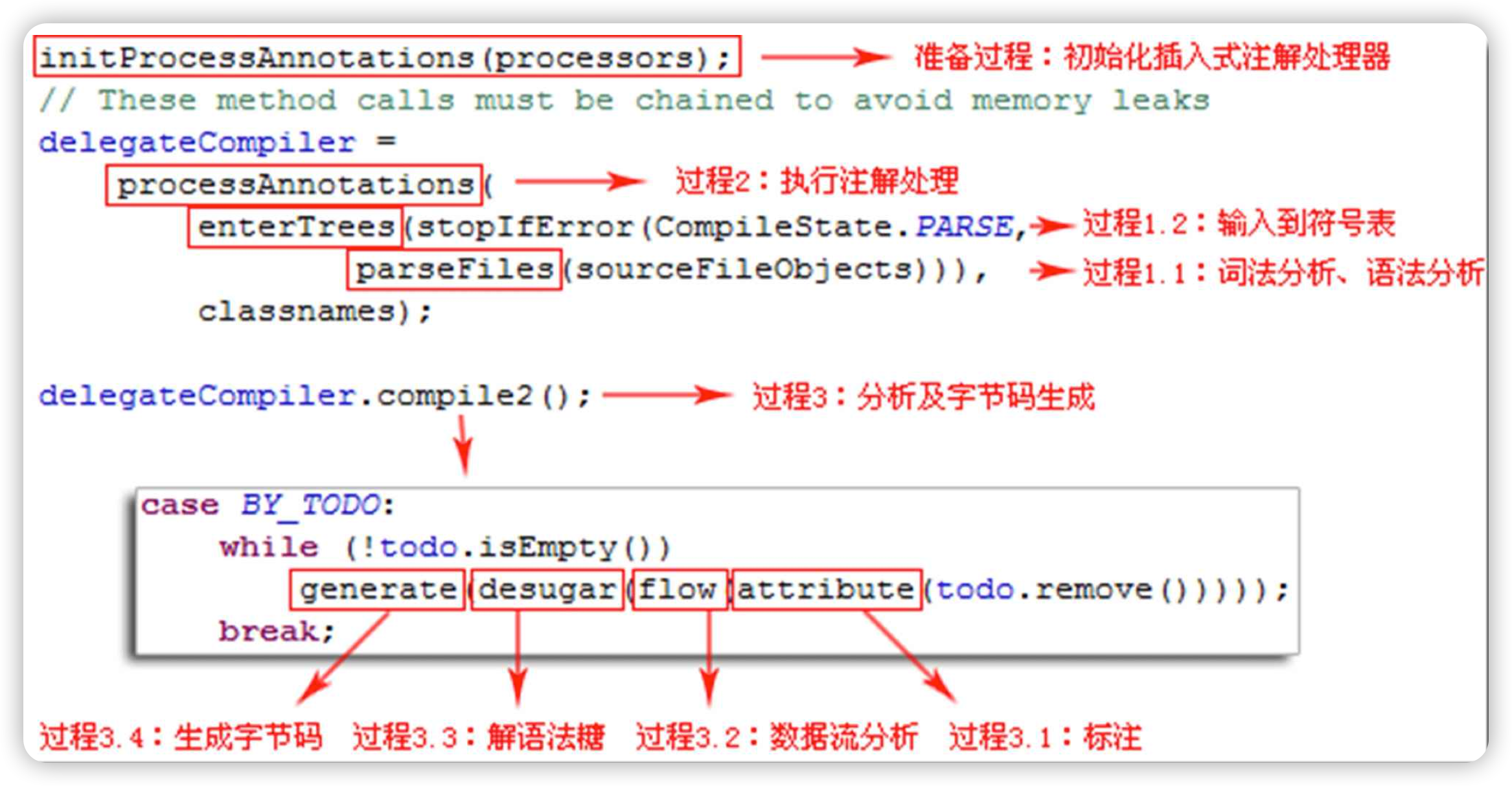
从Javac代码的总体结构来看,编译过程大致可以分为1个准备过程和3个处理过程:
- 准备过程:初始化插入式注解处理器。
- 解析与填充符号表过程,包括:
- **词法、语法分析。**将源代码的字符流转变为标记集合,构造出抽象语法树。
- **填充符号表。**产生符号地址和符号信息。
- **插入式注解处理器的注解处理过程。**执行插入式注解时又可能会产生新的符号,如果有新的符号产生,就必须转回到之前的解析、填充符号表的过程中重新处理这些新符号。
- 语义分析,解语法糖与字节码生成过程,包括:
- **标注检查。**对语法的静态信息进行检查。
- **数据流及控制流分析。**对程序动态运行过程进行检查。
- **解语法糖。**将简化代码编写的语法糖还原为原有的形式。
- **字节码生成。**将前面各个步骤所生成的信息转化成字节码。
源码com.sun.tools.javac.main.JavaCompiler类:
2.1.1. 解析与填充符号表
包括经典程序编译原理中的词法分析和语法分析两个步骤:
-
词法、语法分析(#parseFiles方法)
**词法分析是将源代码的字符流转变为标记(Token)集合的过程,单个字符是程序编写时的最小元素,但标记才是编译时的最小元素。**关键字、变量名、字面量、运算符都可以作为标记,如“int a=b+2”这句代码中就包含了6个标记,分别是int、a、=、b、+、2,虽然关键字int由3个字符构成,但是它只是一个独立的标记,不可以再拆分。在Javac的源码中,词法分析过程由com.sun.tools.javac.parser.Scanner类来实现。语法分析是根据标记序列构造抽象语法树的过程,抽象语法树(Abstract Syntax Tree,AST)是一种用来描述程序代码语法结构的树形表示方式,抽象语法树的每一个节点都代表着程序代码中的一个语法结构(Syntax Construct),例如包、类型、修饰符、运算符、接口、返回值甚至连代码注释等都可以是一种特定的语法结构。
-
填充符号表(#enterTrees方法)
**符号表(Symbol Table)是由一组符号地址和符号信息构成的数据结构。符号表中所登记的信息在编译的不同阶段都要被用到。**譬如在语义分析的过程中,符号表所登记的内容将用于语义检查(如检查一个名字的使用和原先的声明是否一致)和产生中间代码,在目标代码生成阶段,当对符号名进行地址分配时,符号表是地址分配的直接依据。
2.1.2. 插入式注解处理器
“插入式注解处理器”是一个标准API,由与一般只在程序运行期间发挥作用的注解不同,这个API可以提前至编译期对代码中的特定注解进行处理,从而影响到前端编译器的工作过程。
插入式注解处理器初始化由#initPorcessAnnotations方法完成,处理过程则由#processAnnotations过程完成。
我们可以把插入式注解处理器看作是一组编译器的插件,当这些插件工作时,允许读取、修改、添加抽象语法树中的任意元素。如果这些插件在处理注解期间对语法树进行过修改,编译器将回到解析及填充符号表的过程重新处理,直到所有插入式注解处理器都没有再对语法树进行修改为止,每一次循环过程称为一个轮次(Round),这也就对应着2.1.图中的那个回环过程。
最典型的一个应用:Lombok。
2.1.3. 语义分析,解语法糖与字节码生成
经过上述步骤,编译器得到了程序代码的AST(抽象语法树)的表示,但是源程序语义未必符合逻辑,因此需要对源程序进行检查,这就是语义分析的任务。
- 语义分析分为标注检查&数据及控制流分析两个过程:
- 标注检查(#attribute方法):
- 检查比如变量使用前是否被声明,变量与赋值之间数据类型是否匹配等问题。
- 常量折叠优化(int a = 1 + 2 → int a = 3)
- 数据及控制流分析(#flow方法):对程序上下文逻辑进一步验证,检查比如程序局部变量在使用前是否有赋值、是否所有受查异常都被正确处理等。
- 标注检查(#attribute方法):
- 解除语法糖(Syntactic Sugar)由#desugar方法完成。
- 字节码生成由com.sun.tools.javac.jvm.Gen类完成。字节码生成阶段不仅仅是把前面各个步骤所生成的信息(语法树、符号表)转化成字节码指令写到磁盘中,编译器还进行了少量的代码添加和转换工作。(比如实例构造器()方法和类构造器()方法就是在这个阶段被添加到语法树之中的)
2.2. Java语法糖
语法糖(Syntactic Sugar)能够减少代码量、增加程序可读性,但对编译结果和功能并没有实际影响。
2.2.1. 范型
泛型的本质是参数化类型(Parameterized Type)或者参数化多态(Parametric Polymorphism)的应用,即可以将操作的数据类型指定为方法签名中的一种特殊参数,这种参数类型能够用在类、接口和方法的创建中,分别构成泛型类、泛型接口和泛型方法。泛型让程序员能够针对泛化的数据类型编写相同的算法,这极大地增强了编程语言的类型系统及抽象能力。
泛型的实现方式:
- 类型擦除式(Type Erasure Generics),比如Java,只在程序源码中存在,编译后的字节码文件中全被替换为裸类型(Raw Type),在相应地方插入了强制转型代码。
- 具现化式范型(Reified Generics),比如C#,无论是程序源码还是编译后的中间语言(Intermediate Language),范型都切实存在。
关于范型擦除:
-
例子:
package com.masaiqi; import java.util.HashMap; import java.util.Map; /** * test type erasure generics * *@author<a href="mailto:masaiqi.com@gmail.com">masaiqi</a> *@date2022/7/25 20:24 */ public class TestTypeErasureGenerics { public static void main(String[] args) { Map<String, String> map = new HashMap<>(); map.put("1","a"); map.put("2","b"); System.out.println(map.get("1")); System.out.println(map.get("2")); } }对编译后的代码执行反编译:
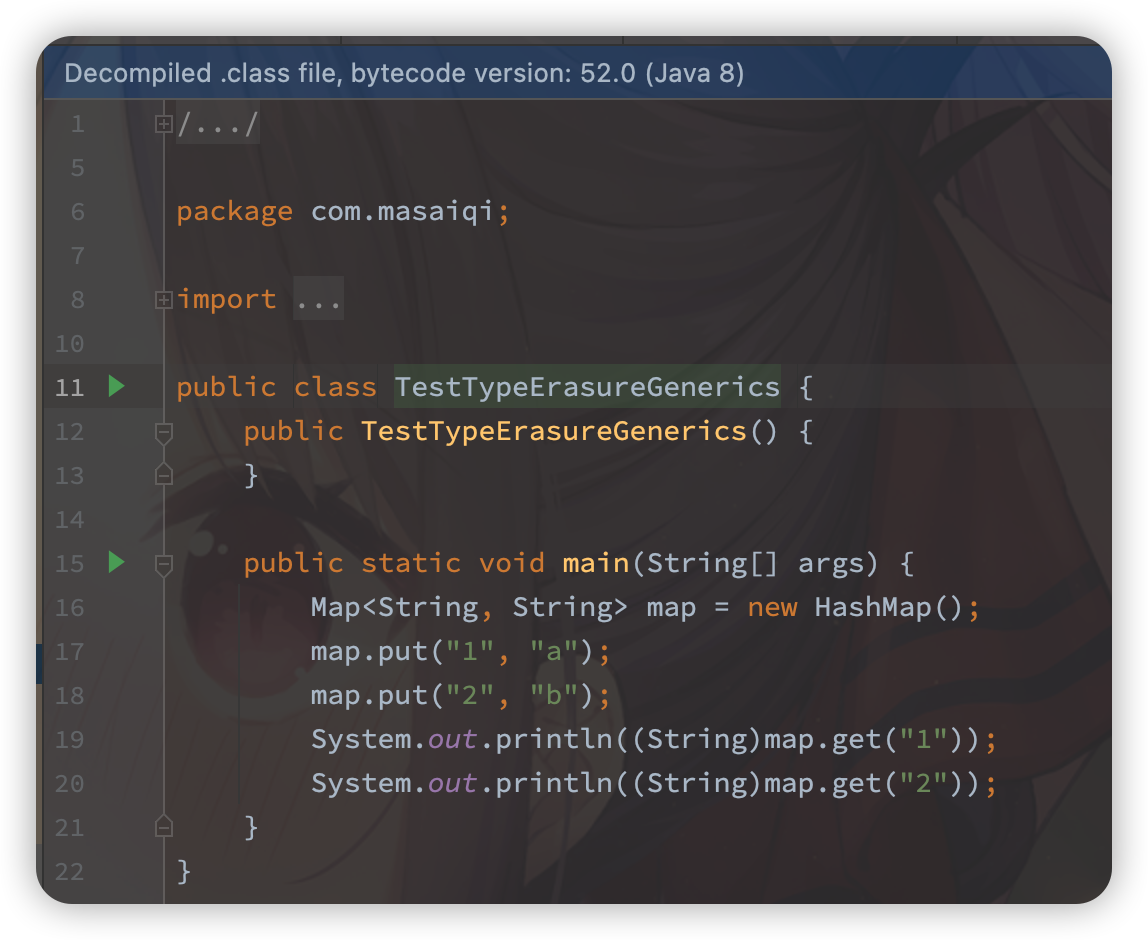
范型消失了,都变回了裸类型,在访问的位置加入了强制转换代码。
-
因为涉及类型转换,因此Java范型不支持原生类型(非一个可转换的类)。
2.2.2. 自动装箱、拆箱与遍历循环
Demo:
package com.masaiqi;
import java.util.Arrays;
import java.util.List;
/**
*@author<a href="mailto:masaiqi.com@gmail.com">masaiqi</a>
*@date2022/7/25 20:33
*/
public class Test2 {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4);
int sum = 0;
for (Integer i : list) {
sum += i;
}
System.out.println(sum);
}
}
编译后反编译:
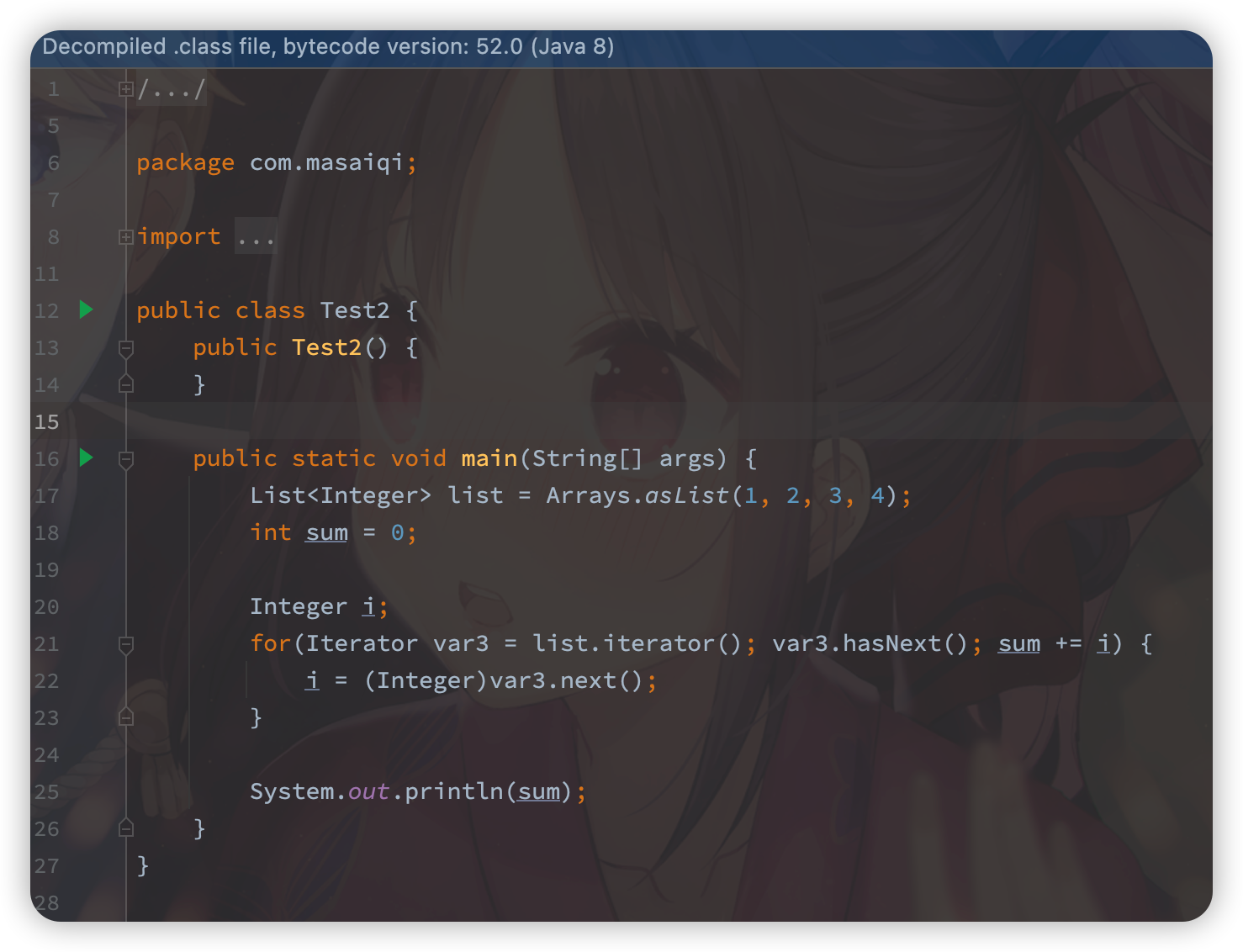
可以看到:
- 原生类型数字1,2,3,4在遍历时,被自动装箱(转换)为Integer类。
- for-each loop被转换为了迭代器遍历。
3. 后端编译&优化
3.1. 即时编译器
当虚拟机发现某个方法或代码块的运行特别频繁,就会把这些代码认定为“热点代码”(Hot Spot Code),为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成本地机器码,并加以代码优化,这个任务由即时编译器完成。
3.1.1. 解释器与即时编译器并存架构
HotSpot虚拟机使用了解释器与即时编译器并存的架构,同时配置有多个不同的即时编译器应对不一样的使用场景。
解释器与即时编译器相互配合:
-
当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即运行。当程序启动后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码,这样可以减少解释器的中间损耗,获得更高的执行效率。
-
当程序运行环境中内存资源限制较大,可以使用解释执行节约内存(如部分嵌入式系统中和大部分的JavaCard应用中就只有解释器的存在),反之可以使用编译执行来提升执行效率。
-
解释器还可以作为编译器激进优化时后备的“逃生门”(如果情况允许,HotSpot虚拟机中也会采用不进行激进优化的客户端编译器充当“逃生门”的角色),让编译器根据概率选择一些不能保证所有情况都正确,但大多数时候都能提升运行速度的优化手段,当激进优化的假设不成立,如加载了新类以后,类型继承结构出现变化、出现“罕见陷阱”(Uncommon Trap)时可以通过逆优化(Deoptimization)退回到解释状态继续执行。
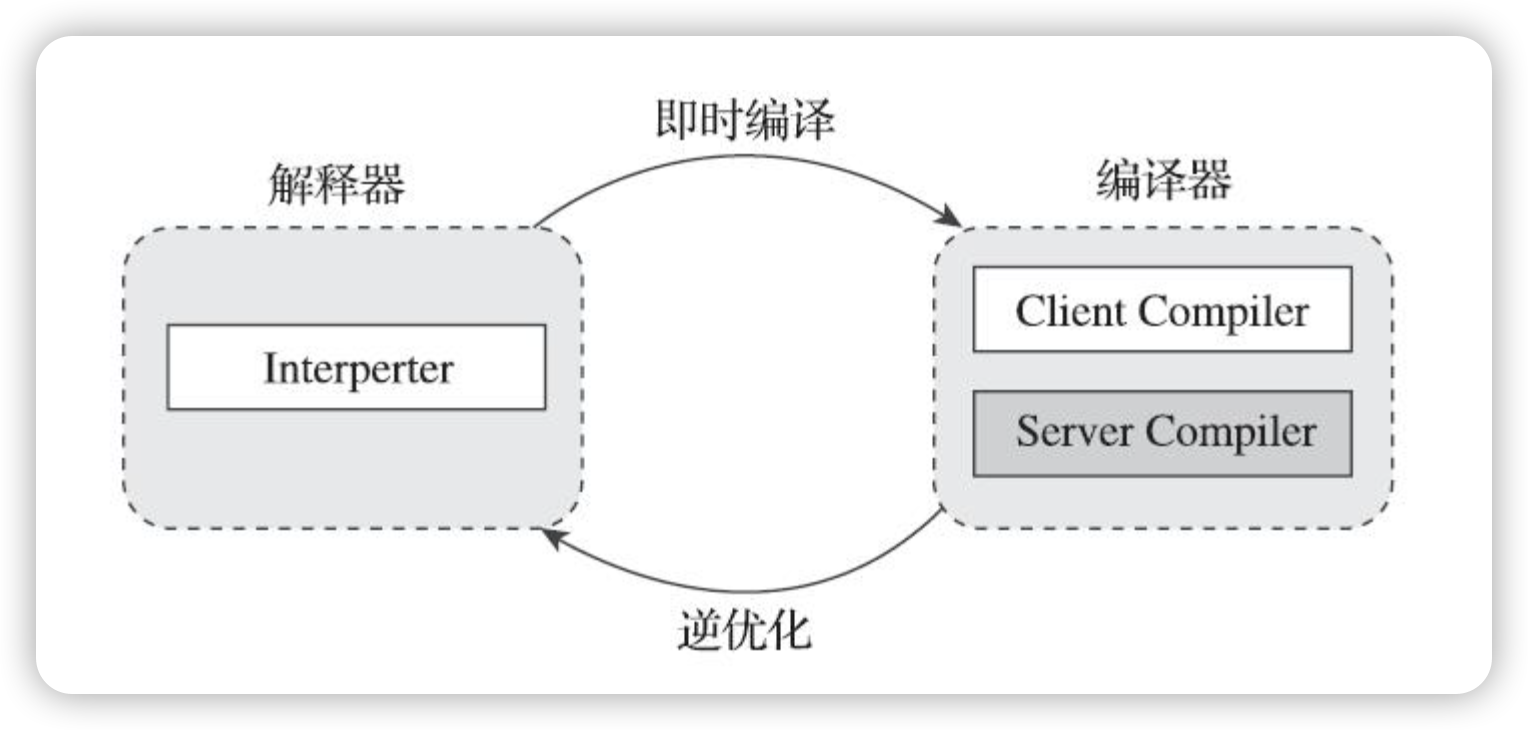
HotSpot虚拟机内置了多个即时编译器:
- C1编译器(客户端编译器,Client Compiler)
- C2编译器(服务端编译器,Server Compiler)
- Graal编译器(目标代替C2,JDK10+)
HotSpot的分层编译(服务端默认开启):
解释器、客户端编译器和服务端编译器同时工作,热点代码都可能会被多次编译,用客户端编译器获取更高的编译速度,用服务端编译器来获取更好的编译质量,在解释执行的时候也无须额外承担收集性能监控信息的任务,而在服务端编译器采用高复杂度的优化算法时,客户端编译器可先采用简单优化来为它争取更多的编译时间。
3.2. 提前编译器
提前编译器可以把程序编译成与目标机器指令集相关的二进制代码。
提前编译器两种实现:
-
在程序运行前把代码编译成机器码,这样会破坏Java的平台无关特性,但是会换取执行效率的提升,否则只通过即时编译器优化,则要占用程序运行时间和运算资源。
-
动态提前编译(Dynamic AOT,或叫即时编译缓存,JIT Caching)。给即时编译器做缓存加速,改善Java程序后需要预热才能达到最高性能问题。
受益于即时编译器的优化,这样做有几个好处:
- **性能分析制导优化(Profile-Guided Optimization,PGO)。**HotSpot的即时编译器在解释器或者客户端编译器运行过程中,会不断收集性能监控信息,根据这些性能数据为导向进行优化。
- **激进预测性优化(Aggressive Speculative Optimization)。**即时编译器优化不同于静态优化需要和优化前完全一样,可以又一些”冒险“的优化措施,如果有问题也有一些对应的”逃生门“(比如解释器执行)挽回。
- **链接时优化(Link-Time Optimization,LTO)。**Java语言天生就是动态链接的,一个个Class文件在运行期被加载到虚拟机内存当中,然后在即时编译器里产生优化后的本地代码。