1. Top Level
聚合设计是DDD战术设计中的一部分。通过有界上下文划分团队,使用统一语言命名上下文;聚合设计则是进入有界上下文内部讨论其结构。
如果说有界上下文解决了领域内的划分,那么聚合就解决了有界上下文内对象之间的划分。所谓划分就是将紧密的放一起,让松散的更加松散,甚至没有关系。从这里能看出DDD的一种收缩趋势,各领域分别向以聚合为核心的方向设计。
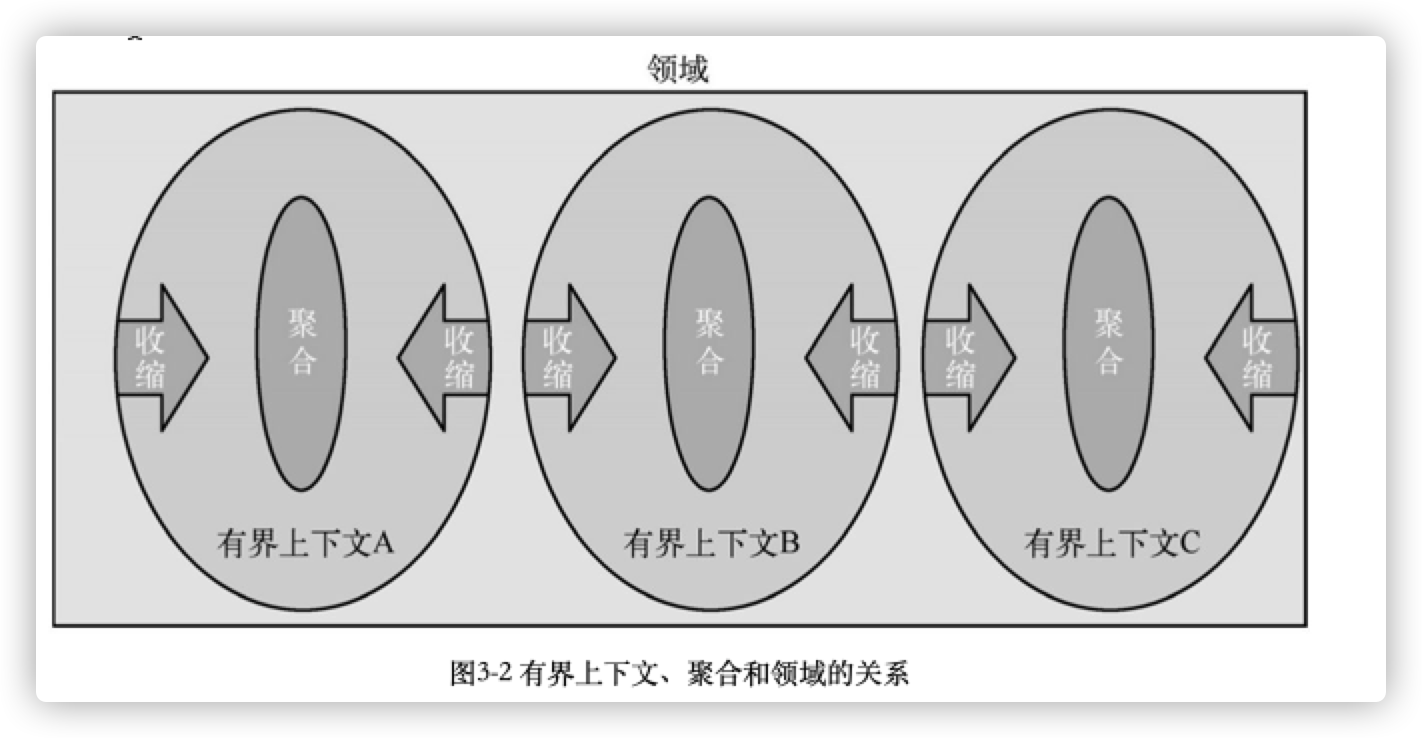
2. 聚合设计的概念
聚合是DDD中的一个重要概念,它对外代表的是一个整体,类似于一个大的对象,内部是由有主从之分的很多对象组成的。聚合是一个行为在逻辑上高度一致的对象群,注意,它是一个对象群体的总称。聚合的内部结构如同一棵树,每个聚合都有一个根,其他对象和聚合根之间都是枝叶与树根的关系。
复杂(Complex)的结构通常使用树形结构来表达,从大自然角度看,树形结构比比皆是,雪花、闪电、河流和人体器官,甚至自然形成的街道,而且这些树形结构中都是分形,也就是枝叶的形状类似整个树的形状。
物理学中的构造定律(ConstructalLaw),它解释大自然是如何实现复杂演化规律的,由AdrianBejan于1995建立,其定义是:对于一个有限大小的持续活动的系统,它必须以这种方式发展演进——提供一种在自身元素之间更容易访问的流动方式。这种结构方式能让实体或事物更容易地流动(变化增加),消耗最少的能量到达最远的地方,就连街道和道路这些人为构建的物体,往往也是有序的模式,以提供最大的灵活性。使用构造定律可以实现无序复杂性的有序化。
笔者理解这里是作者借用自然规律(构造定律)解释有序化是符合自然规律的,有序更加灵活,且有很多好处。
有序化的好处是:只有“根”能引用或指向其他对象,“根”自身不能被其他任何对象引用;“根”类似团队的小组长,队员都要向其汇报工作。这就是聚合根的设计来源,聚合根拥有自己边界内的数据所有权,以及行为职责的管理权限。
2.1. 高聚合低关联
业务逻辑体现在各种数据、行为的关系上,因此,聚合设计也重在关系处理,对关系的敏感性成了设计聚合的要点。
聚合本身就是一种高聚合,聚合内部的对象都是在数据和行为上高度关联和一致的,除此以外的其他关系就被抛弃了。这里鲜明地主张了一种非黑即白的可行动的设计理念——如果关系不是很紧密,那么就隔断,如果非常紧密就放在一起。
在类的关联上,有一种关系叫聚合(Aggregation),聚合关系是一种更强的紧密关联,代表一个类是另一个类的一部分。有两个特性:
- 传递性:如果A是B的一部分,B是C的部分,那么A就是C的一部分。
- 反对称性:如果A是B的一部分,那么B不会是A的一部分。
除了聚合还有组合(Composition)。组合是一种较强的聚合关系,这两种关系基本相同,不同之处在于,在组合关系中,部件对象任何时候只能从属于一个整体对象,两者的生命周期是一样的。
而DDD中的聚合设计就是要找出这两种更强的关联。它们都是比普通关联更加严格紧密的关系,普通关联关系就可以舍弃,这正是高聚合低关联的设计原则
2.2. 聚合的逻辑一致性
**业务逻辑的一致性需要从两个方面去保证:业务数据和业务行为。**这两个方面缺一不可,正如传统系统中,如果只设计数据表结构,而没有SQL调用,就不能实现业务逻辑,同样,如果只有SQL调用,而没有事先设计的表结构,业务逻辑同样无法得到实现。
实现逻辑一致性是聚合存在的根本目的。高聚合低关联只是体现逻辑一致性的一个方面,更多的逻辑一致性不但体现在结构关系上(业务数据结构),还体现在行为动作的执行上(业务行为)。
2.2.1. 业务数据(结构)
高聚合低关联,可以看成是从结构关系上确立业务对象的紧聚合关系,割裂除了聚合以外的关系,这样业务对象就能形成一个有主从之分的结构,而不是如同蜘蛛网那样混乱的关系结构。
2.2.2. 业务行为
业务逻辑的一致性还体现在行为的逻辑关系上:
- 行为发生是有顺序的
- 行为发生是一致的(比如即使部分数据变化了,其他数据也应该跟着变化整体达成一致)
这些行为的逻辑关系往往是业务规则,而聚合是保证业务规则实现的地方。一般相同业务规则会在同一个有界上下文中实现,具体来说就是在聚合中实现。
2.2.3. 结论与目标
聚合的逻辑一致性是最终在聚合根这个类中实现的,那么类的行为就成为逻辑一致性最终落地的保证。如何通过类的行为保证逻辑一致性?可以从职责角度去设计:
- 决定(deciding):为了做一个决定,一个对象也许需要知道一些信息。
- 知道(knowing):为了知道某些信息,一个对象也许需要做一些事情。
- 做(doing):为了做某个事情,一个对象也许需要知道一些信息。
为了规范从职责行为思考领域的习惯,可以引入按合约设计(DesignbyContract,DBC)模式,它分三个部分。
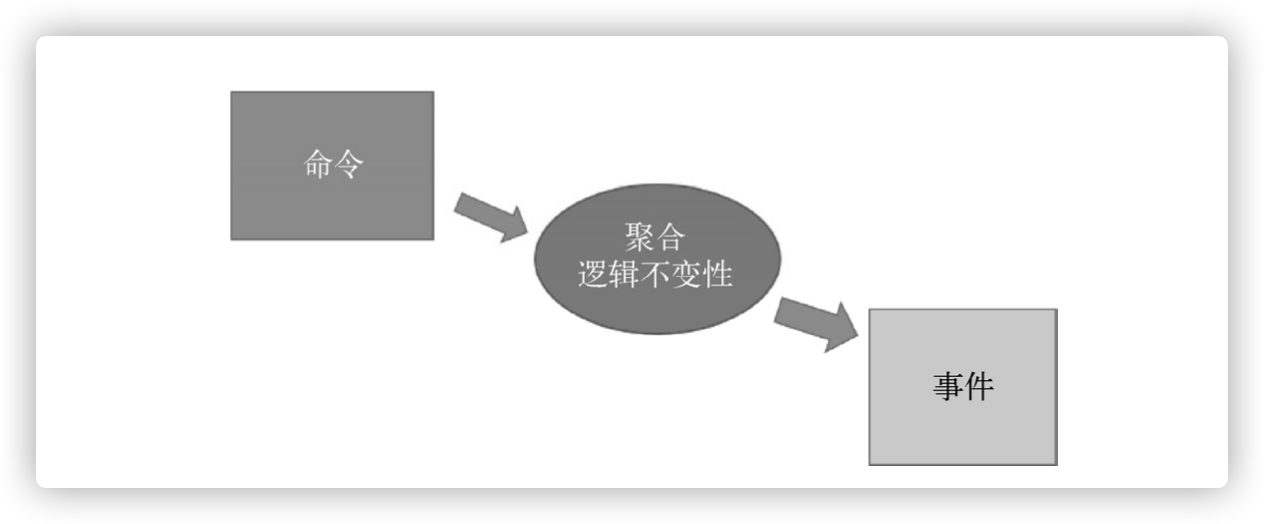
- 预先条件:职责行为发生条件。包括:何时/何地/为什么/如何触发、策略、约束和委托行为,这个可以使用“命令”表达。
- 后置条件:在一个对象被认为处于一个新状态时,应该通过什么标志来判断,返回结果或断言,这个可以使用“领域事件”表达。
- 不变性:描述了一些专有特征不应该在行为事件发生后变化(主要是业务规则或逻辑一致性等),无论这个类有多少实例,也无论它什么时候被其他对象访问。
这里重点强调的是 命令 + 事件 + 不变性。
3. 设计聚合的几种方法
聚合代表一种高度紧密的关系,下文表述如何从有界上下文中设计这些高聚合的紧密关系。
3.1. 改变主谓宾顺序
一般人可能对主语比较敏感,这里所谓改变主谓宾顺序是强调更加关注“谓语动词”,进而找到聚合关系。
3.2. 根据领域事件
领域事件是在有界上下文的聚合中发生的。

通过领域事件发现有界上下文(比如上文中的事件风暴会议),更进一步,有界上下文发现了,下一步就是有界上下文内的聚合。命令是具体落到聚合根这个对象上,当聚合根根据业务规则或逻辑执行了这个命令,实际上就代表聚合根内部的状态发生了改变,一些事实发生了,聚合根再抛出领域事件。
传统数据库设计是先有数据表才有关系表,而DDD的革命性正是在这里——先有关系才有关系内的对象,这也是维根斯坦逻辑哲学中“对象只有在关系中才有意义”的一个体现。
3.3. 根据单一职责设计聚合
聚合的逻辑一致性不但表现在紧凑的结构关系上,还表现在高度一致、高度凝聚的职责行为上,这也是OOAD中单一职责的一个实现。
从职责角度,聚合模型有以下特征:
- 信息拥有者模型。当一个对象是信息的拥有者时,它的职责是“知道这些信息”,不应该期望和其他对象协作获得这些已经知道的信息。
- **决策控制者模型。控制者是和协作者有区别的,控制者能区分事情,决定采取什么行动;而协作者通常是让它做什么就做什么,自己很少做决定,没有主见。**可以从决定性行动来自哪里来寻找控制者,一般决策都来自业务规则,如果这些决策是复杂的,则使用聚合中其他对象分担责任。
在设计聚合时,需要将聚合模型和服务模型进行区分。聚合与服务模型的区分是控制者与协作者的区别:如果一个对象监听用户的动作命令,然后简单委托请求给周围的一些对象,它是在传递做决策的职责,也就是说,它在请求决策控制者做决策,它自己并没有做决策;它也可能做些控制者模型让它做的一些协调工作。协作是只做一些与聚合对象之间的请求响应互动,协作模型描述的是“how”、“when”以及“withwhom”等动态行为,协作相当于管道布线,服务只是聚合与外部的管道布线。
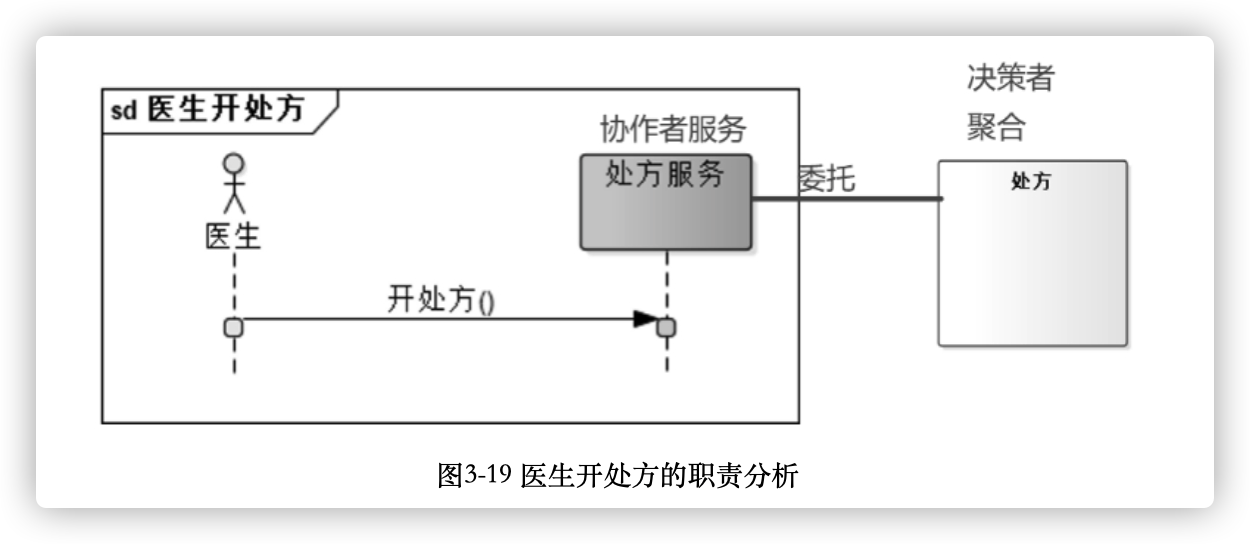
好的面向对象设计是服务与聚合实现邻居式的组合,每个单位有独特的职责。每个对象都扮演一个角色,也都知道向哪个邻居求助,职责在邻居间共享。当聚合或服务对象变得很大时,可能需要一分为二,过去一个聚合的职责可能就变成两个聚合之间的协作。当进行聚合划分时,需要重新检查这两个聚合是否有足够理由待在一个有界上下文内,是不是有界上下文没有考虑足够,核心子域与通用/支持子域的主次地位是否之前没有搞清楚。
3.4. 按时间边界设计聚合
既然有界上下文可以通过时间线去发现,那么作为存在在有界上下文中的聚合模型,自然也受到时间线影响。
按照时间边界去发现聚合,可以同时发现聚合和有界上下文,但是要避免在一个有界上下文出现多个聚合,如果一个有界上下文中存在多个聚合,就要区分这几个聚合中是否有主次之分;如果是并列,可否划分成不同上下文;如果有主次之分,是否有核心子域和通用/支持子域之分。总之,最后一定要找出标识当前有界上下文的那个核心标志。
聚合与有界上下文的关系通常是一对一,在一个有界上下文中如果有多个聚合,也需要在多个聚合之中确定主要聚合,遵循主要矛盾与次要矛盾分离的原则。
3.5. 通过事务边界设计聚合
每当发现领域中有两个元素紧密结合在一起时,就有可能会发现潜在的聚合,因为聚合的特点是紧密关联。可以根据这些元素的存储方式发现并设计聚合。
例如:用户必须在注册之前输入姓名、邮件地址,如果没有这两个输入,就应该无法创建账户。也就是说,如果他们不满足业务上所有这些条件,他们创建账户的请求(即事务)将被拒绝。
事务体现了业务规则,这里的业务规则是:在任何情况下,没有姓名和邮件地址的客户都不应存在于系统中,称此为不变业务规则。
在一个事务中,进而可以考虑这几个元素代表的业务概念是否为一个聚合。明白了事务边界代表着聚合边界,就可以根据事务边界来设计聚合了。
3.6. 通过ER模型设计聚合
如果有两种数据表,一种表是主表,另外一种表是明细表,主表是总体概括,或者是明细表发生变动时需要同时修改的共享的一个表,这在ER模型中称为星形模型:
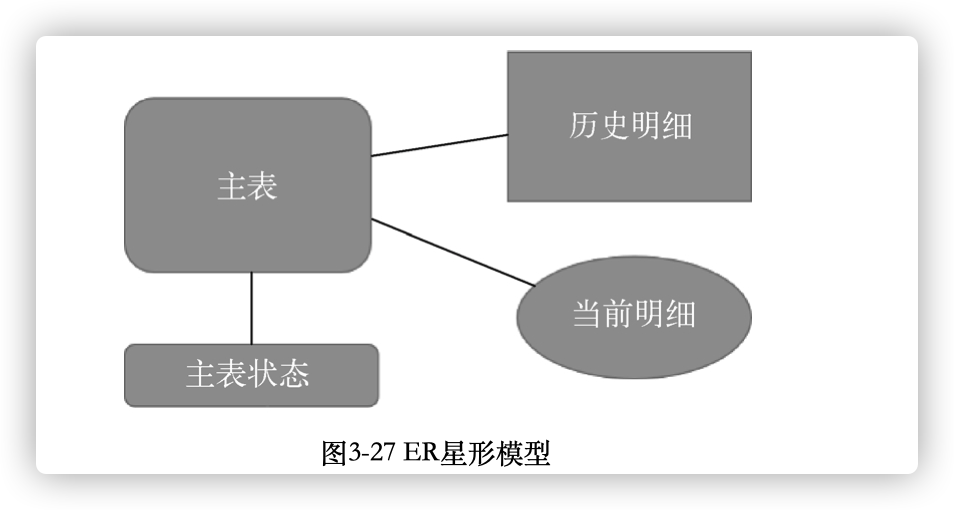
这么E-R模型中往往会发现下面的聚合关系:
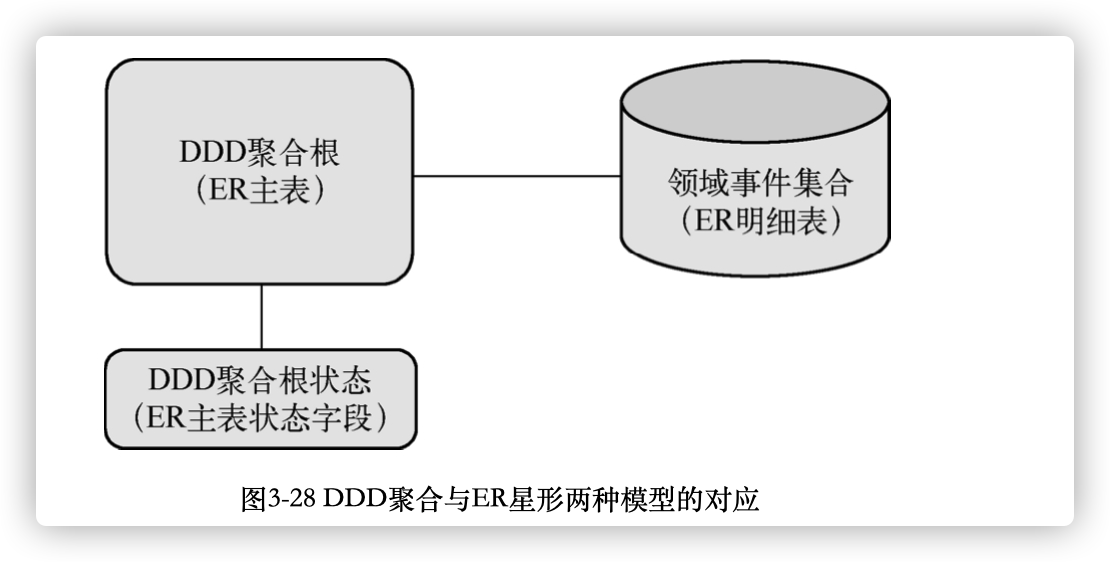
4. 总结
通过引入标识将事物分为主次两个方面,这是DDD建模中主要的思维方法之一:首先将问题空间划分为核心领域和辅助领域,将领域划分为不同的子域,然后集中精力攻克核心领域。在解决方案里,通过逻辑一致性划分有界上下文,找到有界上下文的标识——聚合,再找到聚合的标识——聚合根,当然聚合根也有标识,比如可以是一个ID字段。